
Zadanie problému (kópia z Cz diskusného fóra):
Username musi mit max. 8 znaku, vzdy 4 prvni ze jmena a 4 prvni z prijmeni, pokud ma jmeno nebo prijmeni mene znaku, berou se pouze ty, ktere tam jsou, no a aby to nebylo tak jednoduche, tak nektera jmena jsou duplicitni, takze je na konci cislice, v tomto pripade se vezmou z prijmeni prvni 3 znaky a 4 znak bude ona cislice.
Pro priklad uvedu par zadani a jak by mel vypadat vysledek:
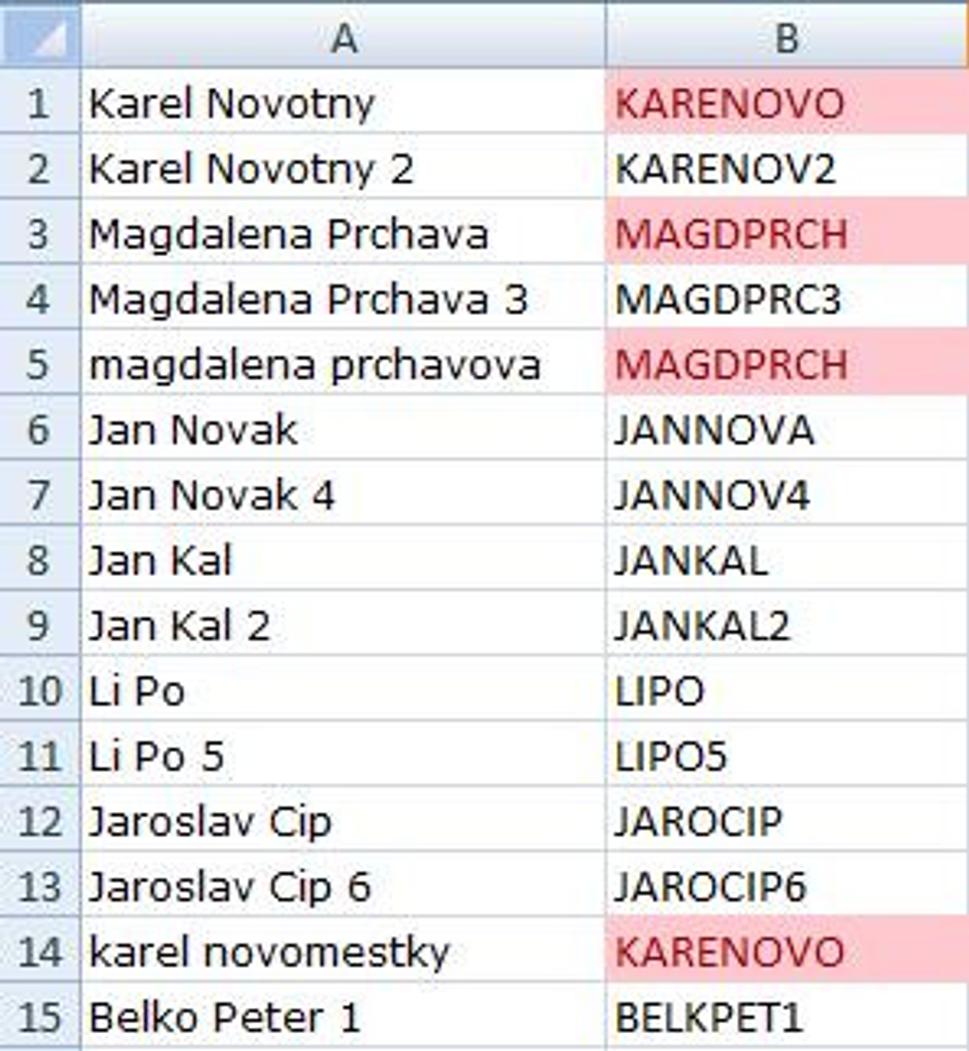
Karel Novotny - KARENOVO
Karel Novotny 2 - KARENOV2
Magdalena Prchava - MAGDPRCH
Magdalena Prchava 3 - MAGDPRC3
Jan Novak - JANNOVA
Jan Novak 4 - JANNOV4
Jan Kal - JANKAL
Jan Kal 2 - JANKAL2
Li Po - LIPO
Li Po 5 - LIPO5
Jaroslav Cip - JAROCIP
Jaroslav Cip 6 - JAROCIP6
Li Novak 5 - LINOV5
Riešenie je založené na postupnom oddelení mena, priezviska a číslice. Použil som na to textové funkcie VELKÁ, ZLEVA, NAJÍT, DÉLKA, PROČISTIT, ČÁST, logickú funkciu KDYŽ a informačnú funkciu JE.CHYBA. Väčšina funkcii sa vo vzorci opakuje, pretože je potrebné urobiť podobné úkony pre jednotlivé časti mena a priezviska.
Prvý krok je oddelenie mena a jeho skrátenie. Na to je možné využiť nasledujúci vzorec: =ZLEVA(ZLEVA(A1;NAJÍT(" ";A1;1)-1);4)
Časť NAJÍT(" ";A1;1) vyhľadáva v zadanom mene a priezvisku v bunke A1, ktoré chceme skrátiť pozíciu medzery. Časť ZLEVA(A1;...-1) skracuje hodnotu v A1 len na meno bez priezviska a bez medzery - to robí tá -1 a časť ZLEVA(...;...-...;4) zobrazuje prvé štyri písmená mena, ak ich je menej, tak zobrazí len tie. Syntax funkcie je ZLEVA(text;znaky), kde text je ten, ktorý chceme skrátiť a znaky je číslo na koľko budeme skracovať. Syntax ďalšej funkcie je takáto NAJÍT(čo;kde;štart), kde čo je hľadaný text, kde je prehľadávaný text (meno a priezvisko) a štart je pozícia kde začne vyhľadávanie.
Druhý krok je oddelenie priezviska. To je možné urobiť takýmto vzorcom:
=PROČISTIT(ČÁST(A1;NAJÍT(" ";A1;1);DÉLKA(A1)-NAJÍT(" ";A1;1)+1))
Časť vzorca ČÁST(A1;...;...-...+1) vyberá len priezvisko a príp. poradové číslo na základe parametrov NAJÍT(" ";A1;1) , ktorý určuje kde sa má začať vyberať časť textu (od pozície medzery) a akú dĺžku má vybrať a tá sa odpočíta z celkovej dĺžky mena a priezviska mínus číslo pozície medzery DÉLKA(A1)-NAJÍT(" ";A1;1). Funkcia PROČISTIT(...) odstraňuje nadbytočnú medzeru na začiatku oddeleného priezviska. Funkcia část má syntax ČÁST(text;štart;počet_znakov), kde text je prehľadávaný text (meno a priezvisko), štart je začiatok kde sa má vybrať text (pozícia medzery + 1) dĺžky určenej podľa parametru počet_znakov .
Tretí krok je skrátenie dĺžky priezviska a pridanie poradového čísla. Na to sa dá využiť nasledovný vzorec:
=KDYŽ(JE.CHYBA(NAJÍT(" ";J1;1));ZLEVA(J1;4);ZLEVA(ZLEVA(J1;NAJÍT(" ";J1;1)-1);3)&ČÁST(J1;NAJÍT(" ";J1;1)+1;1))
Tu sa predpokladá, že odkazujete na bunku, kde je vzorec z druhého kroku (v mojom prípade J1). Znovu je potrebné vyhľadať medzeru NAJÍT(" ";J1;1) aby sme overili či je tam poradové číslo. Ak tam nie je, výsledkom bude chyba #HODNOTA!. Informačná funkcia JE.CHYBA(...)zabezpečuje podmienku v logickej funkcii KDYŽ. Funkciou ZLEVA(J1;4) zabezpečíme priezvisko bez poradového čísla a medzery skrátené na štyri znaky (pravdivá časť podmienky když). V nepravdivej časti podmienky skrátime priezvisko na tri znaky ZLEVA(ZLEVA(J1;NAJÍT(" ";J1;1)-1);3) a doplníme tam poradové číslo ČÁST(J1;NAJÍT(" ";J1;1)+1;1), ktoré vyberieme z reťazca priezvisko a číslo. Tieto dve hodnoty sa spoja znakom &. Syntax logickej funkcie je KDYŽ(podmienka;pravda;nepravda), kde podmienka je logická podmienka (v mojom prípade je to informačná funkcia JE.CHYBA, ktorá je pravdivá ak je v bunke chyba #HODNOTA!), časť pravda sa vykoná pri splnenej podmienke a časť nepravda pri nesplnenej. Štvrtý krok je spojenie všetkých troch vzorcov do jedného „megavzorca", aby bolo splnené zadanie úlohy. Celý vzorec som ešte doplnil o funkciu VELKÁ, ktorá zmení výsledné používateľské mená písané veľkými. Potrebná je aj úprava všetkých odkazov na bunku kde je meno a priezvisko (A1). Namiesto odkazu J1 je potrebné vložiť vzorce z tejto bunky (J1).

Funkciu som vytváral a otestoval v MS Excel 2007 Cz. Funguje bez problémov podľa zadania. V diskusii sa objavili ešte požiadavky na zabezpečenie duplicitných používateľských mien, ale to by som odporučil riešiť podmieneným formátom, ktorý farebne zvýrazní duplicitné položky v stĺpci. Druhá požiadavka, ktorá predpokladá viac ako 9 rovnakých mien a priezvisk tak, aby sa priezvisko skrátilo o znak a doplnili sa dve číslice problém dosť komplikujú a predpokladám, že bez použitia VBA by to asi nefungovalo. Posledná požiadavka je na prípad ak je prehodené meno a priezvisko, ale to si tiež neviem predstaviť, pretože Excel nerozlišuje čo je meno a čo priezvisko ;-) Vyššie popísaný vzorec funguje na akékoľvek textové reťazce v rôznom poradí. Tu by som odporučil preniesť časť práce aj na používateľa, aby si overil duplicity a poradie meno a priezvisko ;-)
PS: netvrdím, že moje riešenie je jediné a rád uvítam nápady a vylepšenia. Odkaz na pôvodné diskusné fórum je tu.






